
the rdf.net challenger – piggy bank
Tim Bray’s latest post reminded me of his rdf.net challenge. Working with various companies on RDF and Semantic Web related tools / products I had forgotten this was still in play. As it still is, i’m interested ![]() . More specifically, I’d like to offer Piggy Bank (and various other tools in the Simile toolkit) as a challenger.
. More specifically, I’d like to offer Piggy Bank (and various other tools in the Simile toolkit) as a challenger.
Reading the (cleverly subjective) criteria of the original challenge
OK, I’m prepared to put my domain name where my mouth is. Herewith the RDF.net challenge: To the first person or organization that presents me with an RDF-based app that I actually want to use on a regular basis (at least once per day), and which has the potential to spread virally, I hereby promise to sign over the domain name RDF.net.
I’ve been using Piggy Bank daily for almost 6 months. Since the latest release a few weeks ago, the stability, speed and performance increases have made this an indispensable tool for me to collect, tag and manage “stuff†that is important to me. Piggy Bank helps me manage contacts, images, news items of interest, scholarly articles, teleconference details, events, web sites of interest, etc. – basically anything I find useful (to date I have about 3000 things i find useful). I figure I save anywhere from 20-30 minutes a day using Piggy-Bank. This give me a couple hours a week more I can spend more with my family – that to me is a killer app!
You can call me an idealist, but I think the Web is terribly metadata-thin, and I think that when we start to bring on board metadata-rich knowledge monuments such as WorldCat and some of the Thomson holdings, we’re damn well going to need a good clean efficient way to pump the metadata back and forth.
I’d argue the Web is actually quite metadata-rich (but my views of the Web go beyond the notion of hyperlinked documents and include the data that is often behind them). The results one gets from searching Monster.com, the listing of available apartments via appartment.com or the nearest starbucks coffee shops based on my zip code are all examples of metadata. The problem isn’t the lack of metadata per se, but the different ways of encoding this information, the ambiguity of terms used to describe this data and the lack of common protocols and interfaces for accessing this data directly. Being able to integrate the data that comes from these sites opens up a whole new set of end-user possibilities (the insomniacs reading this post that would love to see a map of the “show me all of the technology jobs that pay > ‘X’ with appartments that cost < ‘Y’ near coffee shops in city ‘Z’†can see the benefit of integrating this data instantly ![]() )
)
While I believe the semantic web standards (RDF, OWL, SPARQL) are key in helping address these problems in general, Piggy Bank is more focused on making the management and reuse of this data transparent to the user. Its focus is to empower the end-user and make it increasingly easy to access this ‘raw data’ and use / re-use, manage, integrate and share this data with others.
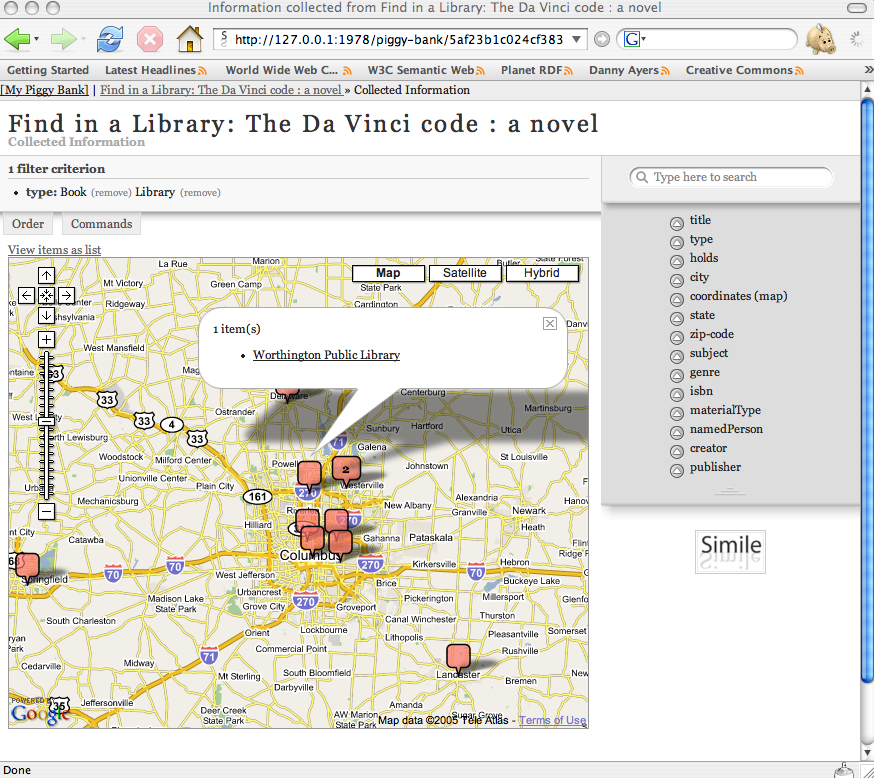
Tim mentioned OCLC’s WorldCat in his original challenge (which aparently has reached 1 billion holdings – congrats!). As a few people know, I previously worked at OCLC for 13 years and have a special place in my heart for libraries. OCLC has recently launched something that call Open Worldcat which provides web access to this data. The problem is (quite selfishly) it doesn’t quite do what *I* want. One of the itches I’ve always wanted to scratch was being able to find libraries that had *all* of the particular items I’m looking for. It’s frustrating to go to a particular library to get “green eggs and ham†and “hop on pop†but somewhere else to getâ€one fish, two fish†(my son likes dr. suess… what can i say). Making this data available on the web however is the key to opening up new end-user applications. Using Solvent and a couple hours trapped in an airport, for example, I exposed this data to Piggy Bank. Using Piggy Bank’s ability to combine information and integrate this with 3rd party services (e.g. Google maps) , I can overlay the results from my queries on a map and create an end-user application that shows the libraries nearest me that has *all* of the books I’m looking for. Using Solvent I’ve created a similar scraper for NCBI’s Pubmed (which has access to 15 million citations from MEDLINE and other life science journals for biomedical articles back to the 1950s). It took me a couple hours to build my first scaper. It took me half that time to build my second. And if others find either one of these useful, it now will take them couple minutes to plug this in to their piggy bank.
Oh, and by the way – the folks really wanting to “show me all of the technology jobs that pay > ‘X’ with apartments that cost < ‘Y’ near coffee shops in city ‘Z’†can do this now – check out the list of scrapers in Simile’s semantic bank.
The decentralized ‘plug in’ architecture of piggy-bank scrapers are a practical stop gap for services that don’t provide their data in RDF. Check out citeseer If you’d like to a quick sense of of a site that does – its far more useful to be to “bookmark†and share individual article level metadata than traditional web page results. For content providers, if you think providing an RSS feeds helps draw people to your site, providing common interfaces to RDF data will make that look trivial in comparison.
There is lots of data on the Web. Piggy Bank simply allows me to the ability to start to use it. I can’t imagine using my computer without access to a browser. Now I can’t image using my browser without piggy bank.
I think the RDF model is the right way to think about this kind of stuff, and I firmly believe that the killer app is lurking in the weeds out there …
The simile team has been focused on getting work done rather than anything else. Now and again, we should remind ourselves to come out from behind the weeds…
Did I win? ![]()